基本检索并不能充分解决回答有效性问题
在我的项目早期,系统的核心结构主要由聊天能力、检索增强生成能力以及基础记忆能力组成。具体而言,系统能够调用文档检索、知识库检索、网页搜索等外部信息源,并在此基础上生成回答。
对于事实性问答任务,这种结构通常是有效的。我们常常认为,只要系统能够获得足够相关的外部信息,模型便可以基于这些信息生成较为可靠的回答。因此,从工程实现角度看,检索增强生成是一种自然且高效的起点。
然而,在实际任务中,这一思想很快暴露出局限性。
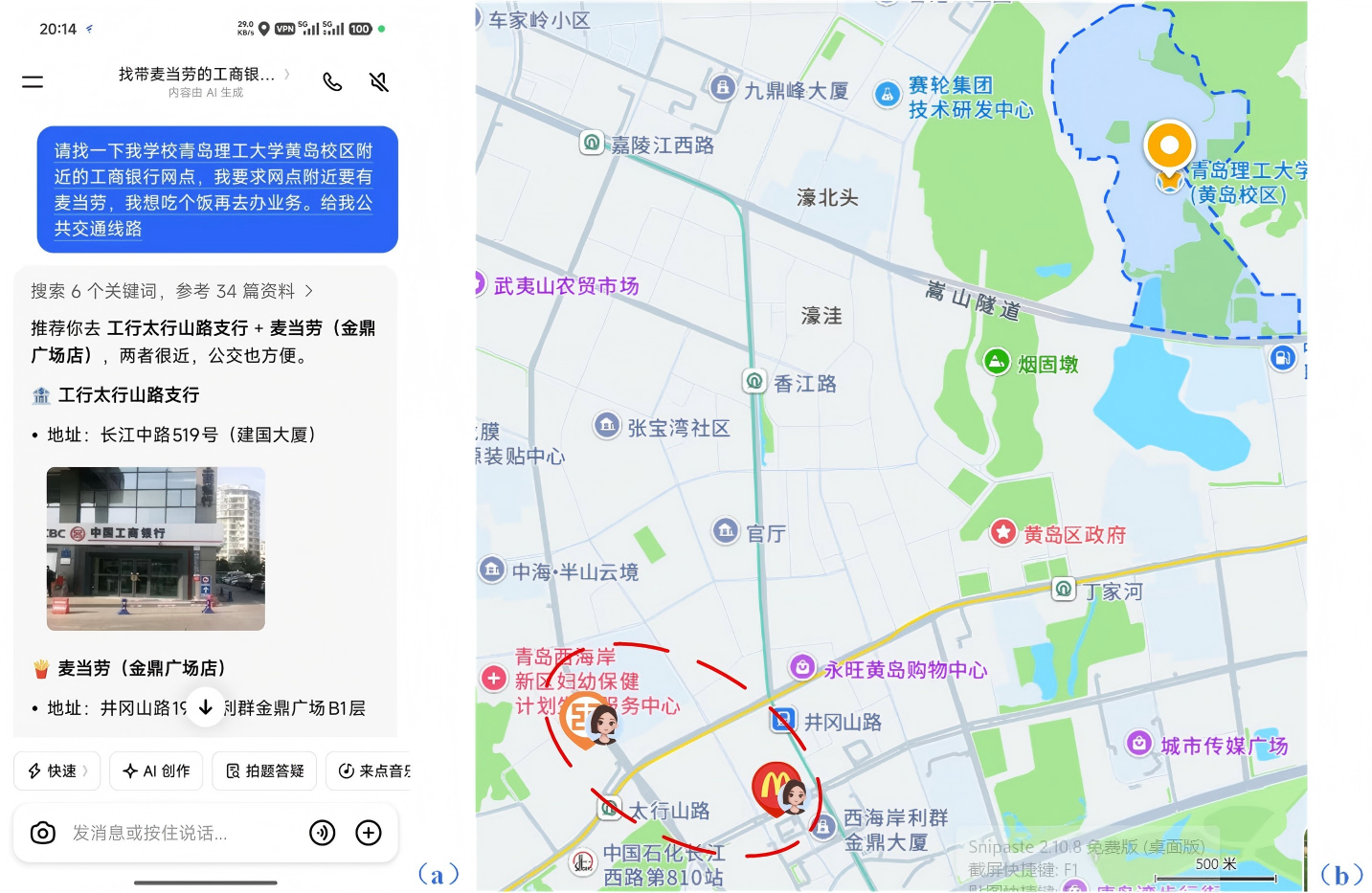
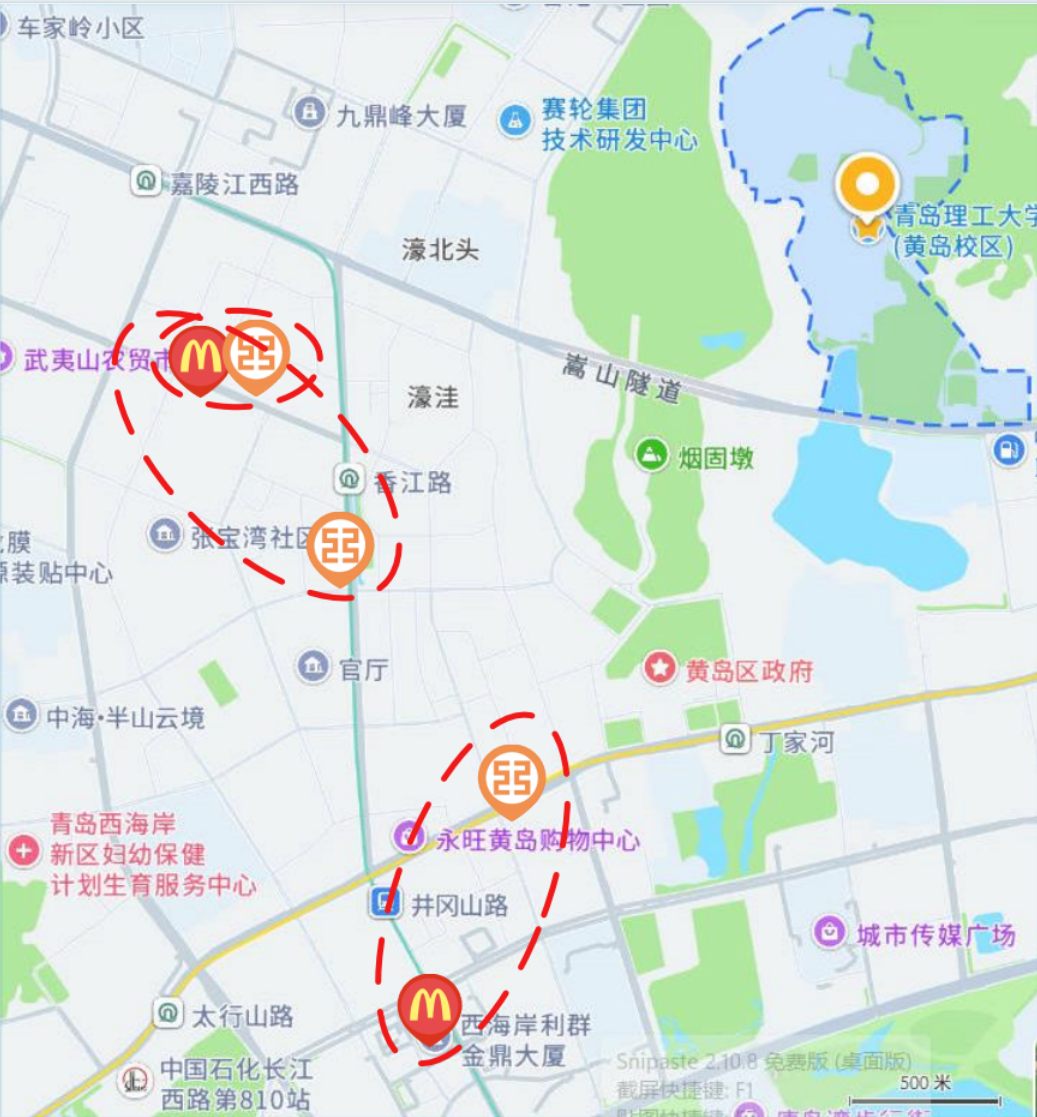
首先,检索结果的增加并不必然带来回答质量的提升。一次检索往往会返回大量候选材料,其中同时包含重复信息、噪声信息以及相互冲突的信息源。部分内容虽然与查询主题相关,但并不适合作为最终回答的直接依据。
其次,部分问题并不能通过单轮检索得到较好的处理结果。系统往往需要先判断问题类型,再决定优先使用哪一种信息来源;在获得初步结果之后,还需要继续判断当前结果是否能够直接用于回答;若证据不足,则可能需要补充检索、调整查询方式,或者进一步向用户确认缺失条件。
所以当系统面对的信息源越来越多、问题类型越来越复杂时,仅依赖 ChatBot与基本检索的组合,已经不足以稳定支撑更高质量的回答过程。
从单轮检索到固定流程
在上一阶段,系统已经暴露出一个明显问题:检索本身并不会自动形成有效回答。既然不同问题依赖的信息来源并不相同,一个自然的改进方向就是先判断问题类型,再进入对应的处理流程。
基于这一想法,我尝试引入固定的Workflow。其基本方式是对用户提问先做意图分类,再进入预设链路。例如,与知识库相关的问题进入知识库检索流程,与记忆相关的问题进入记忆检索流程,与地图相关的问题进入地图查询流程。
但是当遇到需要融合多信息源的问题时,上述的方法便行不通了。例如,“根据我之前提过的偏好,推荐学校附近适合我的咖啡店”这一问题,同时涉及记忆与地图信息。前者用于提供用户偏好,后者用于提供候选地点。但在固定 workflow 下,问题通常会先被归入地图分支,但又因为不知道用户提问的“学校”在哪,无法生成有效的回答。
.png)
让模型主动规划
在固定 workflow 阶段,系统已经能够针对不同问题选择不同的信息来源,但它仍然依赖一个前提,即在回答开始之前先确定主路径。这个前提在处理混合型问题时并不稳定,因此我开始尝试把路径规划本身交给模型。
这一阶段的基本做法是:在接收到问题之后,先由模型进行整体分析,再使用结构化步骤描述后续步骤,例如先检索什么信息、再调用什么能力、最后如何组织结果。随后,系统按照这份计划依次执行。与固定 workflow 相比,这种方式不再要求系统预先写死所有路径,而是允许模型根据具体问题临时生成流程,因此在形式上具有更高的灵活性,解决了上文提到的固定流程无法融合多源信息的问题。
与此同时,我在这一阶段进一步引入了中间态与图模型来组织回答过程。中间态用于保存当前已获得的信息和中间结果,图模型则用于描述各步骤之间的关系与执行顺序。节点之间只需要与中间态进行交互,最终回答生成也只需要参考中间态中所存信息进行回答即可。比如记忆检索节点将检索结果放入中间态,知识库节点将检索结果也放入中间态,最终回答节点直接从中间态中获取记忆信息与知识库检索的相关信息,即可实现按照融合记忆与知识库进行回答。
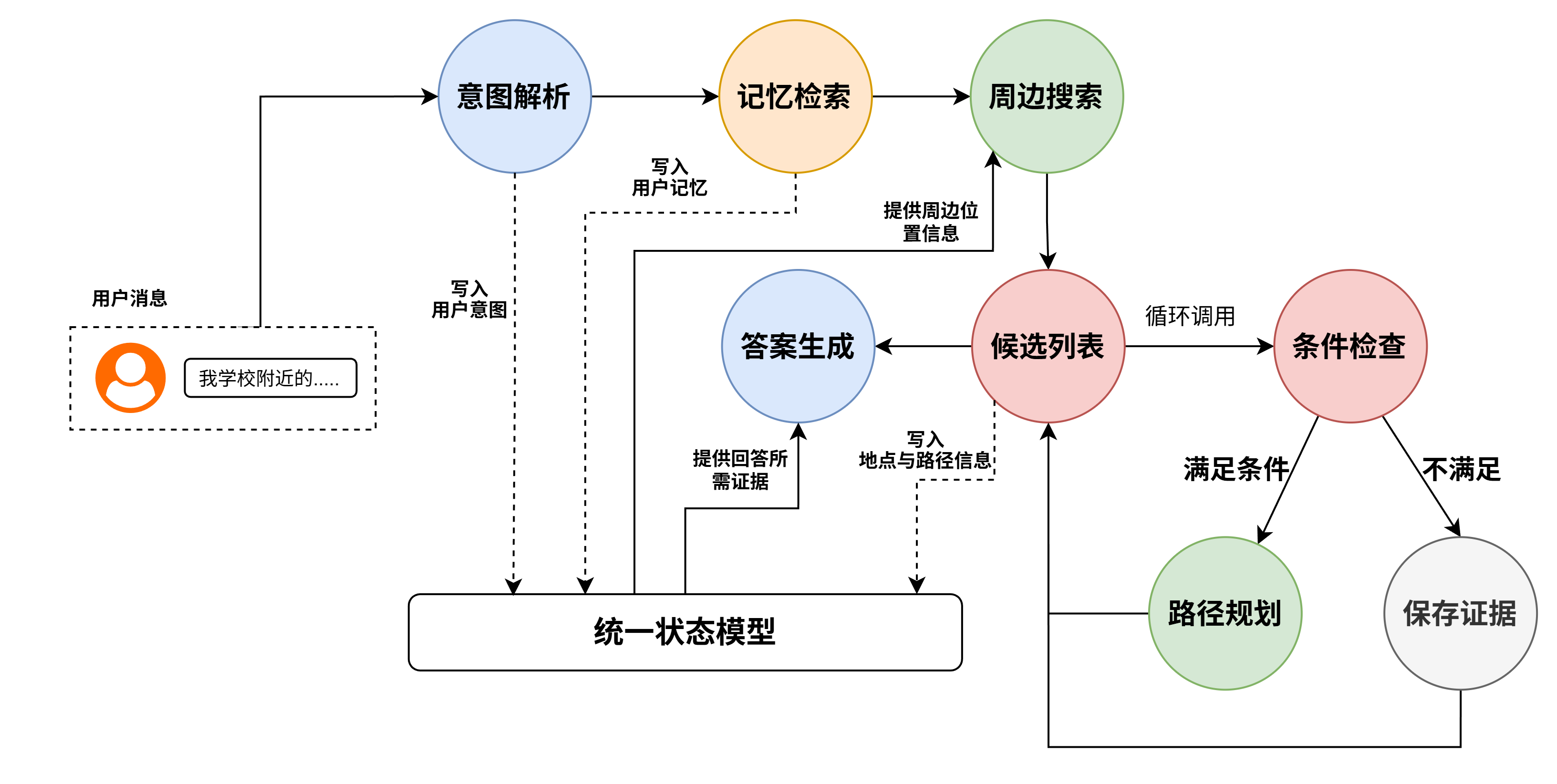
但实际运行后,这种方法很快暴露出新的问题。由于规划是在执行前一次性完成的,生成的步骤往往较长,也较脆弱。一旦执行过程中出现新的情况,例如中间结果与预期不一致、缺少关键条件,或者工具调用失败,原有计划就很容易失效。
并且,如果采取当计划失败,尝试修补计划或者尝试重新生成计划时,所需成本较高,并且速度比较慢,更有可能进行了修补或重试仍无法成功完成任务。
让模型一步一步走
之后,我了解到了ReAct。ReAct(Reasoning and Acting)是一种将推理、行动与观察相结合的任务执行范式,其核心在于构建思考、行动与观察之间的循环机制,从而实现任务的逐步推进。而不是直接一次性生成最终结果。在这一过程中,模型显示基于用户提问、可用工具等其他上下文信息与外部信息进行思考与判断,决定下一步要执行的操作;随后调用提供的工具来获取信息并执行任务;工具返回结果后,模型对结果进行观察:检查工具是否正确被调用,返回的结果是否合理等。同时,观察阶段还会对工具输出的结果进行解析与整理,并将其写入上下文,使得模型在下一轮循环中能够基于真实准确的信息来进行推理与判断,提高 Agent 运行的鲁棒性。
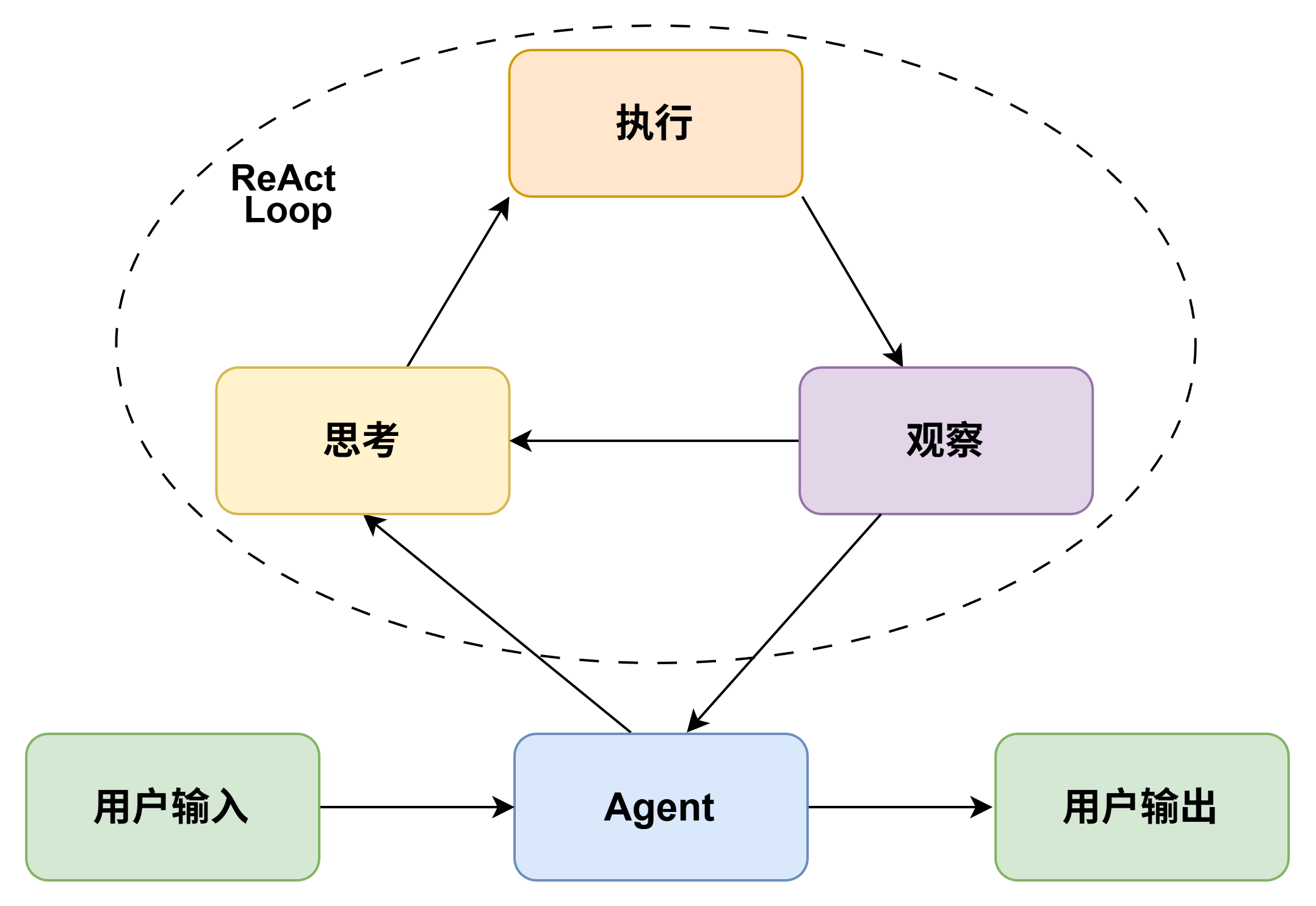
这方式直接缓解了上一阶段的几个问题。首先,当中间结果与原有预期不一致时,系统不再需要回到起点重新规划整条路径,而只需要基于当前结果重新判断下一步即可。其次,当执行过程中发现关键信息缺失时,系统不必依赖一份预先写好的计划强行向前推进,而是可以先停在当前步骤,转而补充所缺失的信息。再次,当某一步工具调用失败或返回结果不足时,系统也不必判定整条路径整体失效,而是可以把失败本身视为当前状态的一部分,再决定是否改用其他信息来源,或调整后续步骤。
对于需要多次循环判断的问题,ReAct 的作用更加直接。由于每一步执行之后都会重新回到判断阶段,系统便可以自然地形成“判断 - 获取信息 - 再判断 - 再调整”的循环结构,允许分支在运行过程中随着中间结果不断展开。这样一来,那些依赖多轮补充信息、反复确认条件、逐步缩小范围的问题,就不再需要被压缩成一条静态计划,而可以在循环中逐步收敛。
与此同时,这一阶段也引入了人在环机制,允许系统在必要时暂停当前过程,并由人工补充缺失信息。这一点与 ReAct 的组织方式是相容的。因为在逐步决策结构下,“暂时无法继续”不再意味着整条路径失败,而只意味着当前状态尚不足以支撑下一步判断。此时,人工补充的信息可以直接进入后续状态,系统再在此基础上继续推进,而不必重新开始整个回答过程。
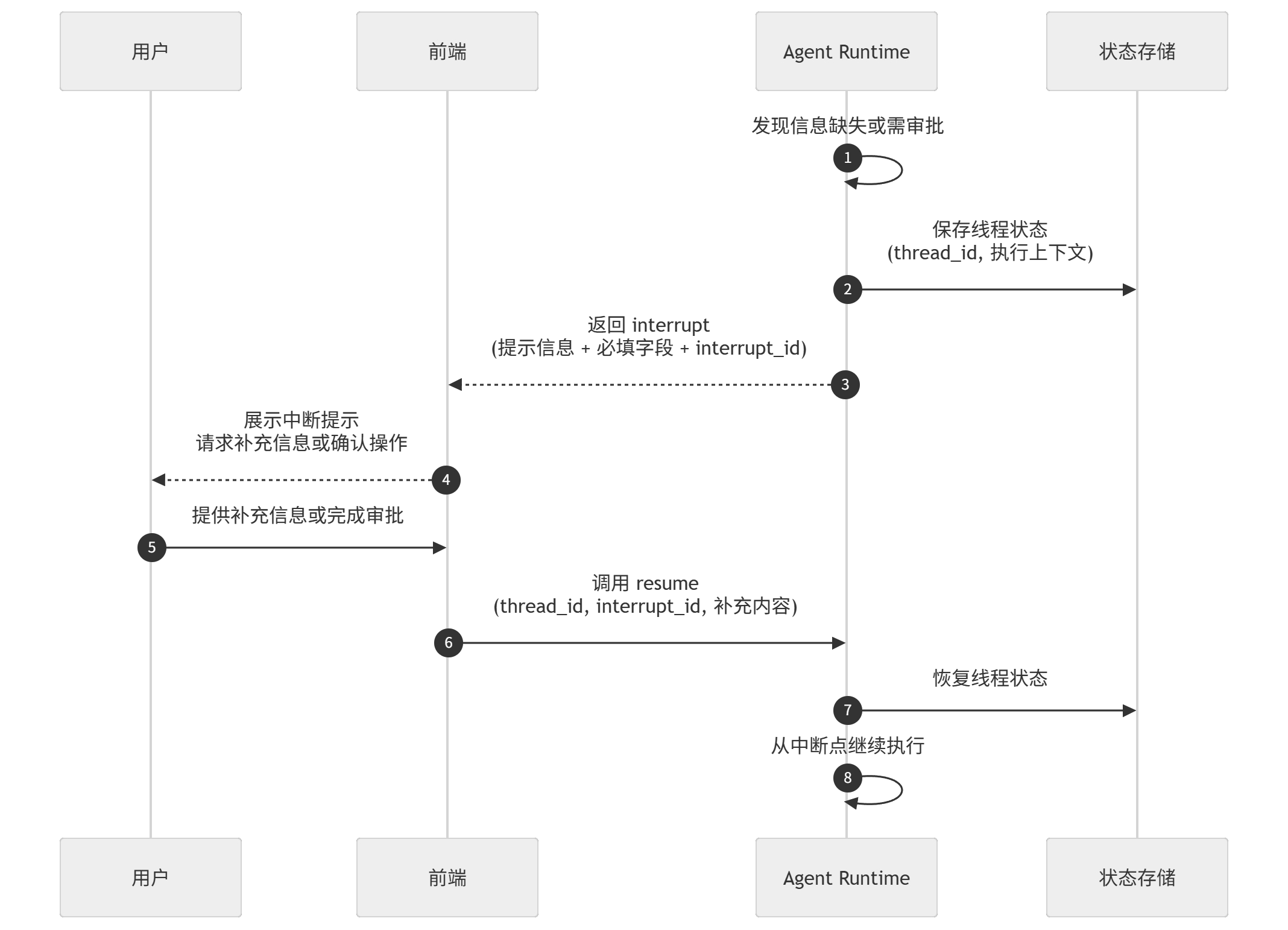
你真的完成了吗
在引入 ReAct 之后,回答过程由一次性规划转向逐步决策。系统不再依赖预先生成的完整路径,而是在执行过程中根据当前状态持续决定后续步骤。这种方式提高了回答过程的适应性,但同时也引入了另一个问题,即系统需要在连续决策过程中判断当前过程是否应当继续、调整或结束。换言之,逐步决策并不自动保证回答过程能够稳定收敛。
基于这一问题,在回答过程中进一步引入了 check point 机制。其作用并不在于生成后续路径,而在于在若干关键节点对当前状态进行显式检查,从而判断当前过程是否已经具备回答条件,是否仍然缺少必要信息,是否需要切换信息来源,或者是否应当进入人工补充阶段。
.png)
这一机制之所以必要,是因为逐步决策虽然能够支持多轮循环判断,但如果缺少额外约束,同样可能导致回答过程偏离预期。较为常见的情况包括三类:其一,系统在仅获得部分信息的情况下过早结束回答;其二,系统在现有信息已经足够的情况下仍继续调用外部能力,造成不必要的过程延长;其三,系统在多个工具或信息来源之间反复切换,却未形成新的有效进展,从而陷入循环。在这些情况下,问题并不在于系统无法继续决策,而在于系统缺少对当前决策结果进行阶段性评估的机制。
check point 的引入,正是为了解决这一问题。在每一个关键阶段,系统都需要对当前状态进行一次检查,并基于检查结果决定后续过程。如果当前信息仍然不足,则继续推进后续步骤,例如改写查询、切换工具或补充新的信息来源;如果现有路径已经无法继续自动推进,则进入人在环阶段,由人工补充关键条件;如果当前证据已经足以支撑回答,则结束后续检索与调用过程,进入最终回答阶段。
写在最后
回过来看,系统的迭代过程并不是从一开始就朝着某种明确的系统形态推进的。很多调整都来自非常具体的问题:检索结果为什么不足以支撑回答,固定流程为什么难以处理混合问题,一次性规划为什么容易失效,逐步决策为什么还需要阶段性判断。也正是在不断处理这些问题的过程中,我才逐渐意识到,复杂回答真正困难的部分,往往不在生成本身,而在回答过程的组织。
但这并不意味着问题已经解决。到目前为止,这类系统仍然存在明显限制。逐步决策虽然缓解了一次性规划的脆弱性,但也带来了新的复杂度,例如过程控制如何保持稳定,阶段性判断如何避免过早结束或过度推进,不同信息来源之间如何形成更可靠的协同,以及人在环机制应当在什么条件下介入。很多时候,系统看起来已经能够“自己往前走”,但距离真正稳定地处理复杂问题,仍然还有相当长的距离。
过去我们习惯于用模型能力、数据规模和检索结果的丰富程度来衡量一个问答系统,但当回答过程本身越来越复杂时,这些指标似乎都不足以单独解释系统为什么有效,或者为什么失效。真正值得继续思考的,也许不是系统一次能拿到多少信息,而是它能否把这些信息与能力组织成一个连续过程,让检索、判断、补充、调整与生成彼此衔接。回答,永远不可能只是一次生成。